| .. | ||
| .gitkeep | ||
| readme.md | ||
散列表
核心:散列表的效率并不总是 $O(1)$,仅仅是在理论上能达到 $O(1)$。实际情况中,恶意攻击者可以通过精心构造数据,使得散列表的性能急剧下降。
如何设计一个工业级的散列表?
散列函数
- 不能过于复杂——避免散列过程耗时
- 散列函数的结果要尽可能均匀——最小化散列冲突
装载因子过大怎么办
动态扩容。涉及到 rehash,效率可能很低。
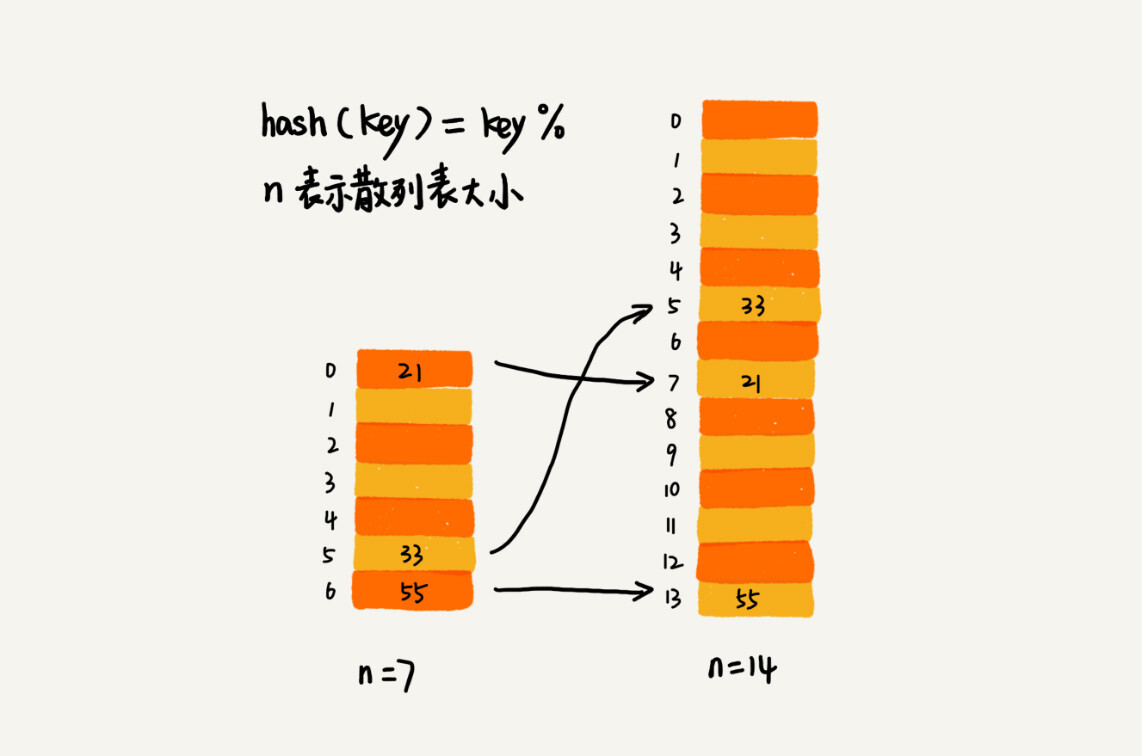
如何避免低效扩容?
——将 rehash 的步骤,均摊到每一次插入中去:
- 申请新的空间
- 不立即使用
- 每次来了新的数据,往新表插入数据
- 同时,取出旧表的一个数据,插入新表

解决冲突
开放寻址法,优点:
- 不需要额外空间
- 有效利用 CPU 缓存
- 方便序列化
开放寻址法,缺点:
- 查找、删除数据时,涉及到
delete标志,相对麻烦 - 冲突的代价更高
- 对装载因子敏感
链表法,优点:
- 内存利用率较高——链表的优点
- 对装载因子不敏感
链表法,缺点:
- 需要额外的空间(保存指针)
- 对 CPU 缓存不友好
——将链表改造成更高效的数据结构,例如跳表、红黑树
举个栗子(JAVA 中的 HashMap)
- 初始大小:16
- 装载因子:超过 0.75 时动态扩容
- 散列冲突:优化版的链表法(当槽位冲突元素超过 8 时使用红黑树,否则使用链表)